
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- OpenAI
- Parallel
- langchain
- webbaseloader
- splitter
- lcel
- Multimodal
- runnablepassthrough
- runnablelambda
- pdfloader
- GPT
- azureai
- chain생성
- azure open ai service
- 자연어 처리
- langsmith
- teddynote
- 자연어처리
- ai language
- runnableparallel
- azure ai
- azure open ai
- csvloader
- Azure
- 챗봇 만들기
- 문서/번역 서비스 사용
- azure services
- RecursiveCharacterTextSplitter
- Runnable
- rag
- Today
- Total
Nathaniel
1-1. GPT-4o 멀티모달 모델로 이미지 인식하여 답변 출력 본문
GPT-4o 모델로 이미지 인식시켜서 답변을 출력해보려고 한다.
GPT-4o는 이미지를 인식하는 기능이 들어가있다!
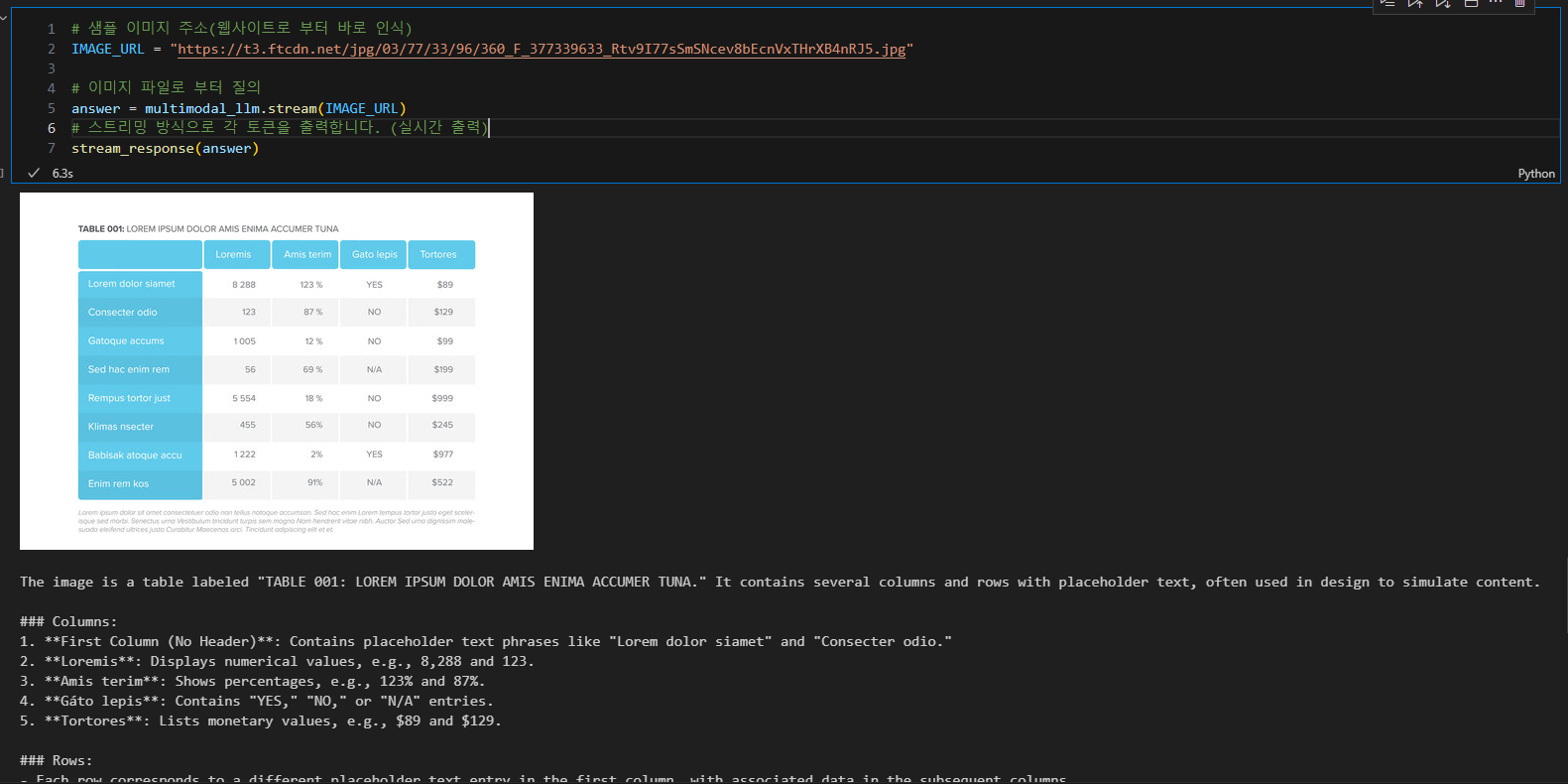
Image_url 주소에 이미지 주소값을 넣으면
Invoke 했을 때 출력되는 부분이 있는데 이때 사진의 표제목을 "LREM IPSUM DOLOR AMIS ENIMA ACCUMER TUNA"라고 읽어준다. OCR 기능이 제대로 작동 되고 있고, 그 외에 열 값에 해당하는 제목들을 읽어서 표에 해당하는 수치값들도 나타내준다.
※ 참고 이미지는 가급적 고해상도의 이미지를 넣어주면 OCR 기능이 제대로 동작하여 해당 텍스트를 잘 읽어들이는 것을 느낄 수 있다.
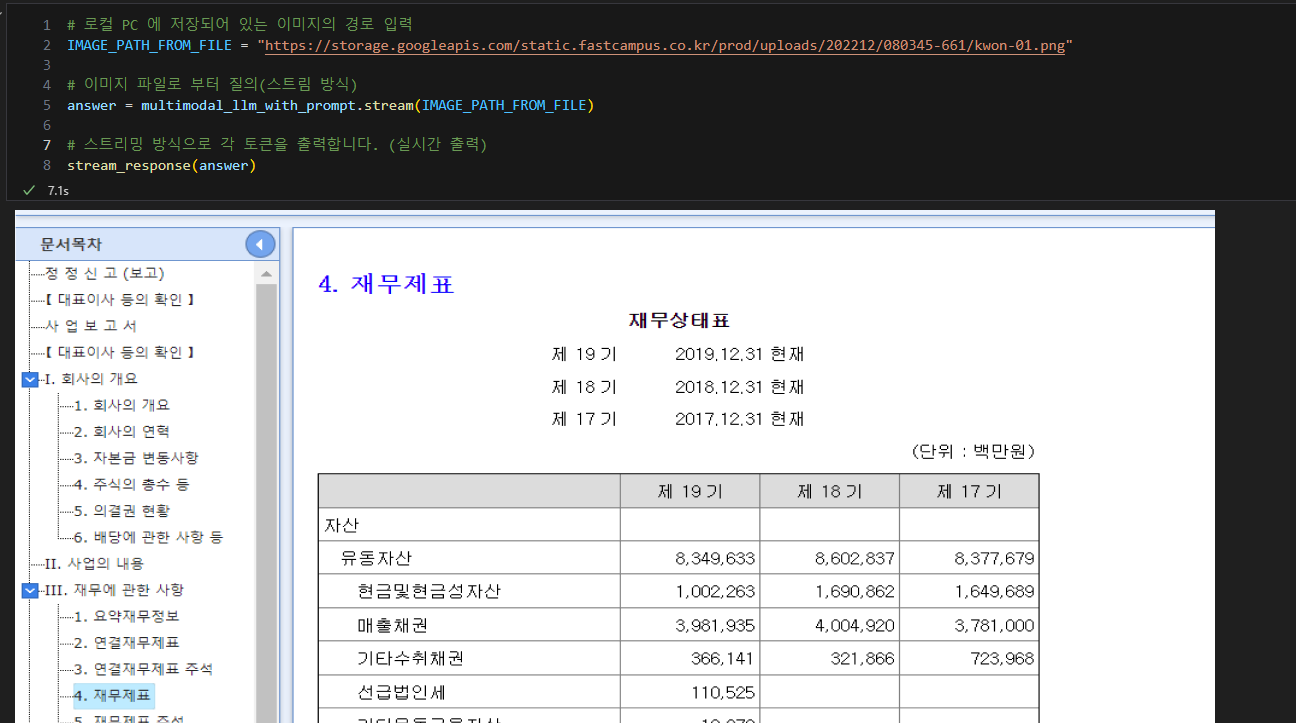
이미지가 웹 주소로 되어있지 않고 로컬에서의 가진 이미지로 해당 Invoke를 받았을 때 아래와 같이 OCR 처리 하는 것을 볼 수 있다. 물론 전에 하던 것과 같이 잘 인식해서 사진의 텍스트를 잘 출력해준다.


이후 LangSmith를 들어가 트레이싱 해본 결과, 사용된 토큰 값들이 이전과 달리 많이 사용된 것을 볼 수 있다.
단순히 Question으로 텍스트만을 입력프롬프트로 주었을 때 출력되는 토큰 값들은 엄청 크지 않았는데
OCR 기능이 있는 사진 내부의 글자수를 읽고 수십 배는 토큰이 많이 사용됐다.

그리고 아래는 재무제표의 전문가의 System_prompt를 작성해서 AI에게 "너는 재무제표 도메인 전문가야"등등의 텍스트를 넣으면 답변해주는 AI는 해당 내용을 도메인에 관련해서 인지하게 되고 이후 User_prompt인 내가 물어볼 내용을 재무제표에 대한 사진, 텍스트를 넣었을 때 어떠한 형식으로 답변 줄 수 있는지와 어떻게 비교를 해줄 건지 넣으면 그거에 맞게 답변을 줄 수 있을 것이다.

PDF 문서나 docx 문서를 로더하지 않고, 단순히 사진 형태로 이미지 파일을 넣었을 때 보이는 영역들을 GPT가 답변 줄 것이다. 지금봐도 뭔가 신기하다.
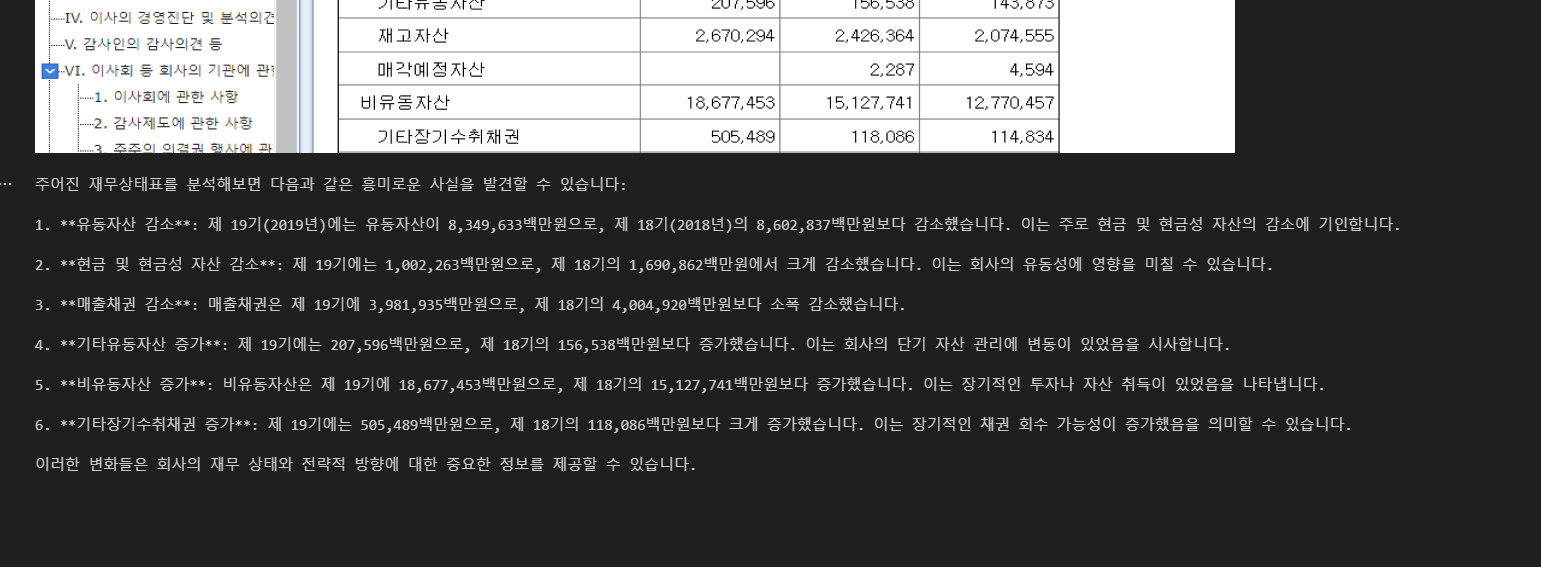
물론 입력 토큰과 출력 토큰이 크긴 하지만, 이미지의 OCR 기능을 잘 해내고 있다는 것을 볼 수 있어 너무 좋은 것 같다.
LangSmith로 토큰 값 확인한 결과 이번엔 더 많은 토큰 값들이 측정 된 것을 볼 수 있다. Window text가 총 120k토큰이 나온 것을 확인할 수 있다.
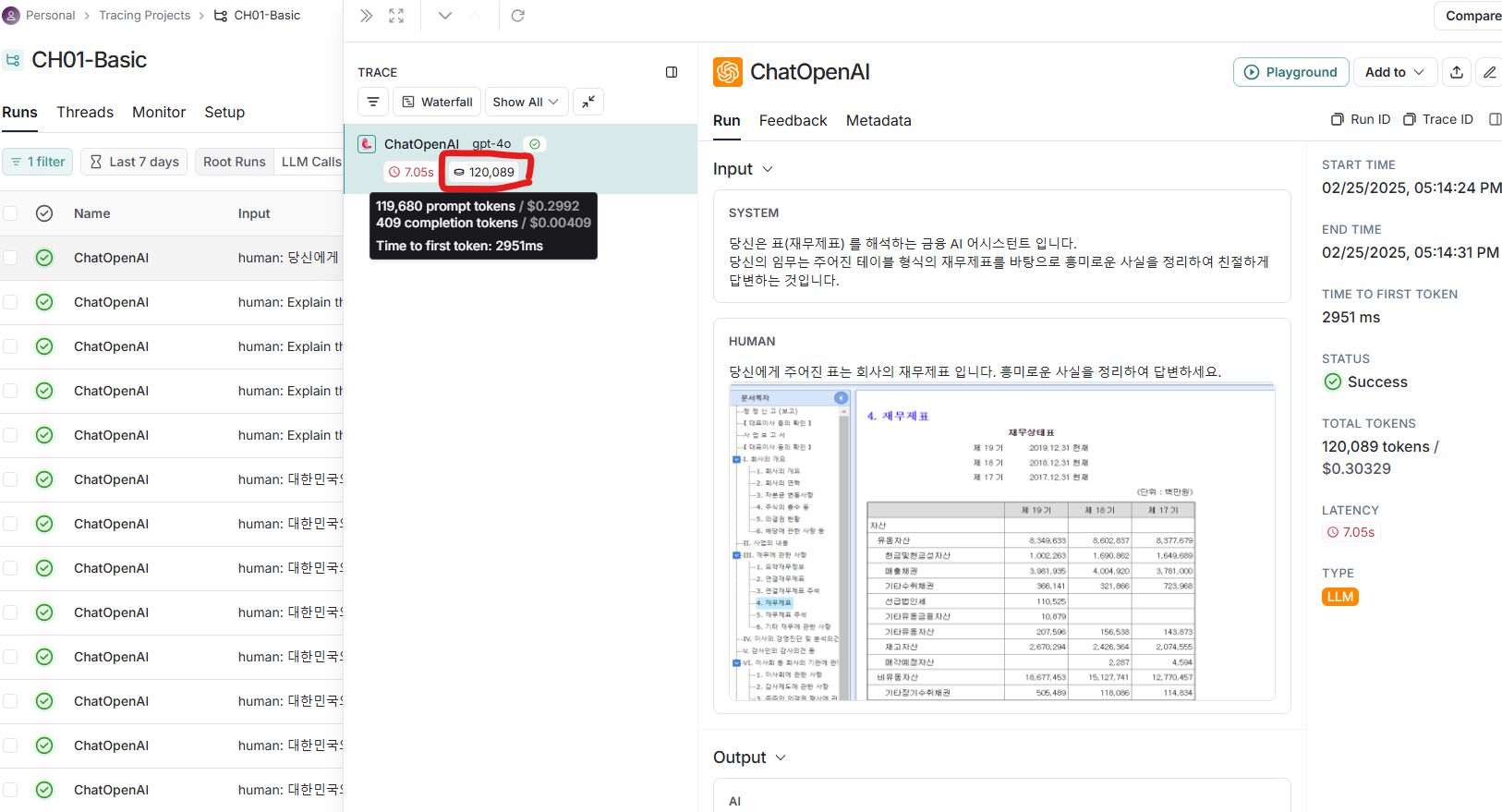
간단하게 GPT-4o 이미지 인식 답변 출력을 해보았다. GPT-4o를 가지고 API 호출하여 이미지 인식하는 기능은 나름대로 재미 있는 것 같다.
'AI' 카테고리의 다른 글
| 4. Runnable(Passthrough, Parallel,Lambda) (0) | 2025.03.02 |
|---|---|
| 3. Langchain LCEL, Parallel (4) | 2025.03.02 |
| RAG 코드 암기하기 D1 (0) | 2025.02.26 |
| 2. Langchain → Chain 생성? (0) | 2025.02.26 |
| 1. OpenAI Langchain, RAG 학습 (0) | 2025.02.25 |



