
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- runnablelambda
- azure open ai service
- 챗봇 만들기
- teddynote
- azure services
- OpenAI
- azure ai
- langsmith
- langchain
- azure open ai
- Multimodal
- lcel
- Runnable
- splitter
- 자연어 처리
- rag
- 문서/번역 서비스 사용
- csvloader
- ai language
- GPT
- webbaseloader
- 자연어처리
- azureai
- Azure
- runnablepassthrough
- RecursiveCharacterTextSplitter
- Parallel
- pdfloader
- runnableparallel
- chain생성
- Today
- Total
Nathaniel
Azure Open AI 활용해서 나만의 챗봇 만들기 24-08-01 본문
Azure Portal GPT 4o 데이터 원본 추가
어제 못했던 데이버 원본 추가하기
등록한 데이터 원본을 활용해서 답변을 하는 것이기에 실습해보려 한다!
※ 참고 Azure에서 Cognitive Search가 → AI Search로 바뀌었다.
실습하기 전에 Blob Storage란?
- 대용량 데이터 저장:
- Blob Storage는 대규모 비정형 데이터를 저장하는 데 사용된다. 예를 들어, 이미지, 동영상, 오디오 파일, 백업 파일, 로그 파일, 빅 데이터 분석 데이터 등이 이에 해당한다.
- 유연한 스토리지 계층:
- Blob Storage는 사용자의 데이터 액세스 패턴에 따라 세 가지 스토리지 계층을 제공한다.
- Hot: 자주 액세스하는 데이터를 저장하며, 저장 비용은 높지만 액세스 비용은 낮음
- Cool: 덜 자주 액세스하는 데이터를 저장하며, 저장 비용은 낮지만 액세스 비용은 높음
- Archive: 거의 액세스 하지 않는 데이터를 장기 보관하며, 가장 낮은 저장 비용을 제공하지만 액세스 시에는 복원 시간이 필요함
- Blob Storage는 사용자의 데이터 액세스 패턴에 따라 세 가지 스토리지 계층을 제공한다.
- 데이터 보안 및 관리:
- Blob Storage는 데이터 암호화, 접근 제어, 백업 및 복원 기능을 제공하여 데이터를 안전하게 보호하고 관리할 수 있음
- Azure Active Directory 및 공유 액세스 서명(SAS)을 사용하여 세밀한 액세스 제어를 설정할 수 있음
- 확장성 및 내구성:
- Blob Storage는 자동으로 확장되어 대규모 데이터를 처리할 수 있으며, 99.999999999%의 내구성을 제공함
- 데이터 복제 옵션을 통해 지역 복제(Geo-redundant) 및 영역 복제(Zone-redundant) 등의 높은 가용성을 보장함
- 통합 및 호환성:
- Blob Storage는 Azure의 다양한 서비스와 통합될 수 있으며, Azure Data Lake Storage Gen2와의 호환성을 제공하여 빅 데이터 분석 및 처리를 지원합니다.
- 다양한 프로토콜과 라이브러리를 통해 쉽게 데이터에 접근할 수 있습니다.
이제 Blob storage를 만들어보자
- Blob storage사용을 위해 스토리지 계정을 생성한다.
- 스토리지는 여러 개가 아닌, 한 개만 만들기 때문에 하나만 생성
- 컨테이너는 접근 권한을 다르게 정할 수 있는 것을 참고할 수 있다.
- AWS는 버킷 개념으로 나눠지고 Azure는 컨테이너 개념으로 나눠진다. 같은 개념으로 쓰기에는 애매하다.
아래 사진은 어제 진행하려다가 멈추었던 채팅 플레이그라운드의 데이터 원본 추가 항목이다.
이 부분이 내가 원하는 학습된 챗봇을 만드는 것이며,
데이터는 간단하게 지역의 치킨집이나, 빵집, 인구분포 등의 CSV 파일을 다운 받으면 된다.
컬럼 데이터가 많으면 그만큼 Json 코드를 수정해줘야 하는 것은 잊지 말도록해!
데이터 원본 출처 : 공공데이터포털 (data.go.kr)


데이터 원본 추가하기 전 작업
- Azure Portal에 들어가서 Marketplace Search 창에 AI search를 검색

Azure AI Search를 클릭하여 Create누르면 아래와 같은 상대로 된다.
- 리소스그룹은 내가 기존에 만들어 두었던 리소스그룹을 선택한다.
- Location은 리소스그룹과 동일하게 정한다.
- 나중에 지역이 달라서 발생할 문제의 확률이 낮기 때문이다.

와... 겁나 비싸다 한 달에 250달러....?

우선, 배포가 되기까지 10 ~ 15분 소요가 된다.
Go to Resource를 눌러 Studio를 들어간다.

나는 스토리지가 없기 때문에 스토리지 계정을 만들어야 한다.
리소스그룹은 기존에 만들었던 내 그룹 이름을 설정
Storage account name은 숫자와 소문자로만 사용해야함. ※ 특수문자 사용 금지!! ex) "-,$,%" 등등
아래는 Storage 계정을 만드는 방법이다.
- Resource group은 당연히 기존에 만들었던 리소스가 자동 선택 된다.
- storage account name은 내가 마음에 드는 거 아무거나 선택한다.

바로 Review + create 누르고 만들어진 go to resource를 누르면 아래와 같은 매뉴바가 생긴다
Containers를 눌러 Blob을 업로드한다.

대충 name은 Openai-data라는 이름으로 지어서 Create를 눌러 만들었다.

업로드하는 파일과 upload to folder를 눌러 기존에 받아두었던 CSV 파일을 업로드를 해야 한다.
그리고 Upload to folder 이름은 내가 알아보도록 지으면 된다.
예) Eat, Travel, Walk 등등

내가 업로드한 CSV 파일을 기준으로 폴더가 하나 생긴 것을 확인할 수 있다. 하지만!!!!!!!
CSV 파일 중에 대부분 데이터를 확인해 보면, 이러한 파일이 많다.. CSV 파일을 VS 코드로 열었을 때
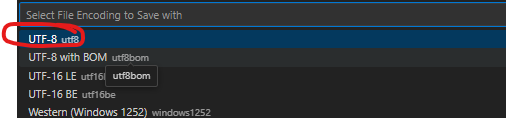
아래처럼 외계어가 보인다면 UTF-8로 변경을 해줘야 한다. VS코드 최하단에 UTF-8을 클릭하고

Reopen with Encoding을 눌러 EUC-KR로 변경한다. 아직 끝난 게 아니다.


Save with Encoding을 들어가서 다시 Save with Encoding을 눌러, UTF-8을 눌러주면 CSV 파일이 한글로 변환된다.

한글로 변환된 CSV 파일을 다른 이름으로 저장해서 Upload blob에 넣어주면 된다.
그러면 아래와 같이 내가 방금 CSV 파일 올렸던 것이 저장된 것을 확인할 수 있다.

다시 Azure 사이트로 돌아와서 내가 만든 리소스 파일에서
Storage account인 Search 파일을 들어간다.(초록색 카드모양 같은 것)

매핑을 하기 위해 만들어 두었던 서치 서비스 파일을 눌러 들어간다
Data sources를 눌러 Add data source를 클릭한다.

- Data source는 Azure Blob storage 데이터 소스를 클릭한다.
- name은 간편하게 내가 알아볼 수 있는 이름으로 사용

- Blob folder는 내가 지정했던 것으로 선택한다.
- 저장하기 전, Choose an existing connection을 눌러 컨테이너를 연결해 준다.

- 컨테이너에 저장된 data를 선택한다.
- Select 클릭하여 Data source를 마무리한다.
Select

Select를 하고 난 후, Travel Dataset이 나오게 된다.

다시 인덱스로 돌아와 Add index를 추가하면 아래와 같은 사진이 나온다.
오른쪽 상단에 위치한 Json 코드에서 코드를 수정 해 넣으면 된다.

아래는 내가 사용했던 Json 코드이다.
{
"name": "travel-index",
"fields": [
{
"name": "id",
"type": "Edm.String",
"key": true
},
{
"name": "name",
"type": "Edm.String",
"key": false
},
{
"name": "address",
"type": "Edm.String",
"key": false
},
{
"name": "latitude",
"type": "Edm.String",
"key": false
},
{
"name": "longitude",
"type": "Edm.String",
"key": false
},
{
"name": "type",
"type": "Edm.String",
"key": false
},
{
"name": "type_number",
"type": "Edm.String",
"key": false
},
{
"name": "telephone",
"type": "Edm.String",
"key": false
},
{
"name": "theme",
"type": "Edm.String",
"key": false
},
{
"name": "has_parkinglot",
"type": "Edm.String",
"key": false
},
{
"name": "parkinglot_count",
"type": "Edm.String",
"key": false
},
{
"name": "homepage",
"type": "Edm.String",
"key": false
},
{
"name": "description",
"type": "Edm.String",
"key": false
}
]
}
그리고 오른쪽을 보면, 필드 이름과 키워드 이름으로 나뉘는데
제목 필드에 'name'이 있기 때문에, 필드 이름에는 'name'이 들어가지 않는다.
그리고 키워드 이름은 내가 검색했을 때 나오는 결과를 받기 위한 키워드이므로 원하는 컬럼을 넣는다.

- 의미체계 구성하는 단계에 내가 원하는 인덱스 구성을 선택하면 된다.
- 물론 CSV 파일에 근거한 데이터를 기준으로 해야 함.
- 다 진행했으면 Save 하고 다시 Travel index에서 Save를 한 번 더 누르면 된다.

그리고 Search Explorer를 눌러 찾으려는 인덱스를 검색한다.
아직 인덱서 매핑이 안되어, 검색이 안된다.
인덱서를 매핑하기 위해 인덱서 추가하러 가보자!

이번엔 검색가능한 인덱서 생성하기를 위해 Add indexcer 클릭

- Name은 travel-indexer
- 어떠한 데이터를 매핑할 것인지를 선택해야 하므로 인덱스에는 index 추가 단계에서 저장했던 데이터를 선택한다.
- 데이터 소스는 travel-dataset으로 선택


다시 Indexer Definition(JSON)을 누른다.
JSON파일의 코드를 추가 입력한다.
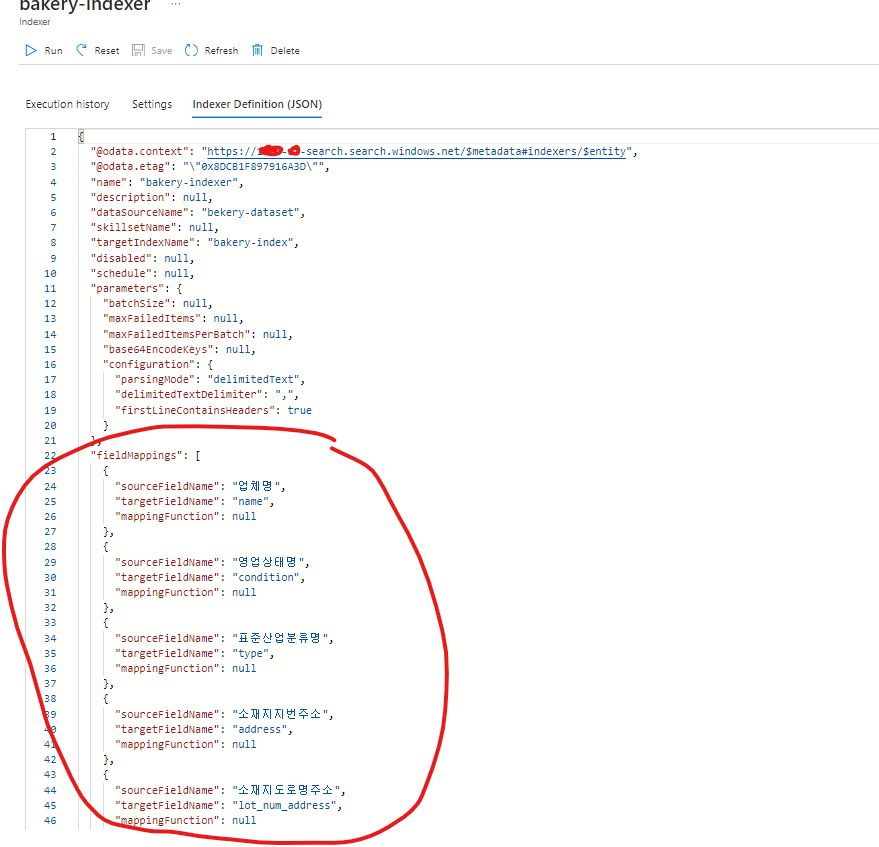
인덱서 Json 코드 추가했으면 이제 저장하고 나가자!!!!!!!!!!!!!!!!!!!!!!!
아래 인덱스 검색에서 남해를 검색했을 때, id, name, address 등등 정상적으로 나오는 것을 확인할 수 있다.

여기 인덱스 검색창에서 '승마랜드'를 검색하면 아래와 같이 주소나, 이름, 위도(latitude), 경도(longitude) 등등 값이 정말 잘 나오고 있다.

하지만 '승마 랜드'로 검색했을 때는 '승마'와 '랜드'의 띄어쓰기를 정확하게 인식해서 데이터가 없다는 것으로 검색된다.
이러한 부분은 정확하게 파악해야 한다.

index와 indexer 매핑이 완료가 되었을 때, 왼쪽 매뉴바에 위치한 '채팅'에 들어가서 데이터 원본 추가를 누른다
원본 추가를 누르면 아래와 같은 것들이 나온다.

- 검색 유형은 의미체계
- 기존 의미 체계 검색 구성 선택은 Travel-semantic 기본 값으로 선택


API까지 설정하고 만들기를 누르면 된다.

고급 설정을 클릭해서 데이터 콘텐츠에 대한 응답 제한 해제를 해두었다.

오른쪽 상단에 배포 대상을 눌러서, 기존 웹앱 업데이트로 배포를 덮어씌웠다.

배포가 다 완료가 되면 Webapp에 돌아와서 내가 만든 웹앱의 도메인 디폴트 도메인 주소로 들어가면 contoso라는 챗봇이 생성된다.
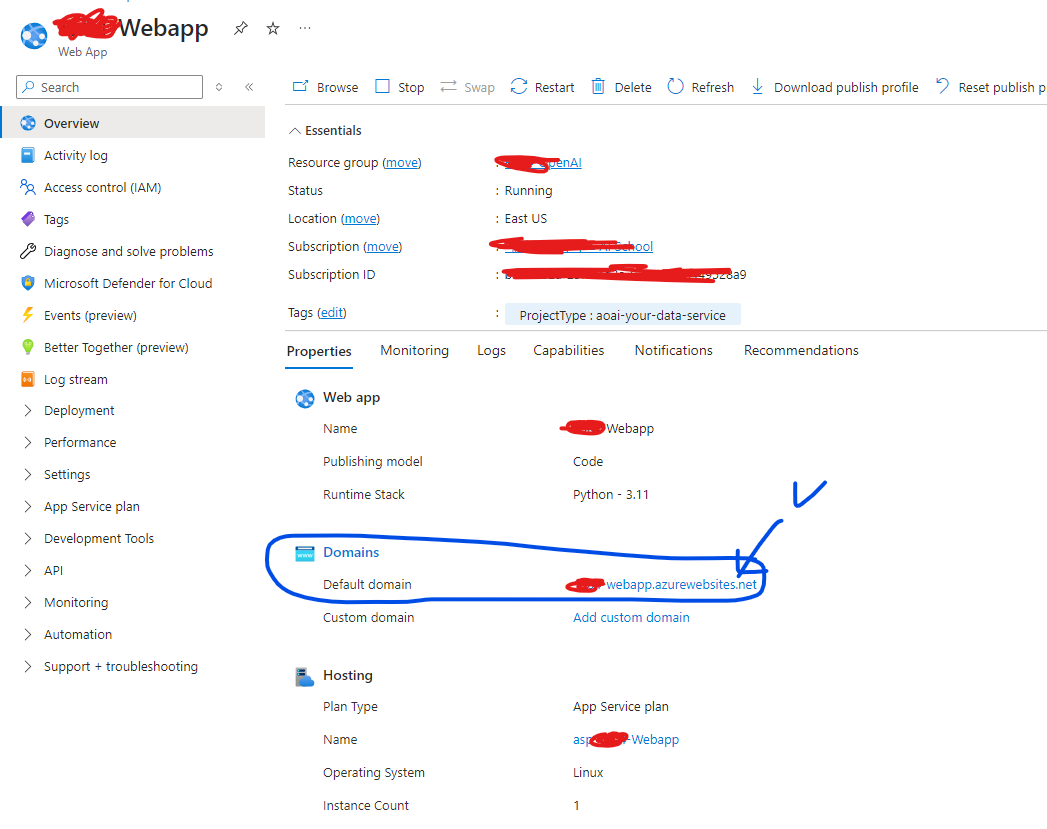
이게 안된다면 아래 사진에서 배포가 완료되었을 때 생성되는 웹앱시작 버튼을 누른다.

드디어 완성~~ 남해 맛집에 관련된 데이터를 chat gpt에 연결시켜서 남해 맛집을 찾고 싶을 때 검색하면 맛집에 특화된 것을 확인할 수 있다.
Contoso가 나오면서, 남해맛집 추천해 달라는 프롬프트를 읽어서 챗봇이 답변을 준다!

이 학습 과정 중 Azure AI Search를 사용하는 것은 Azure가 권장하고 있는 부분이다.
텍스트 분석 및 인덱싱
Azure AI Search는 텍스트 분석 기능을 통해 문서의 의미를 이해하고, 이를 바탕으로 효율적인 인덱싱을 수행합니다. 이를 통해 대량의 데이터를 빠르게 검색할 수 있다.
이 과정들은 학습된 데이터를 내려주는 것이고, fine tuning과는 별개이다.
※ Fine tuning은 먼저 학습된 모델을 업데이트하는 방법이며, 모델의 파라미터를 미세 조정하는 것이기 때문이다.
번외로 아래는 다른 CSV 파일을 컨테이너로 저장해서 빵집 데이터를 학습시켜 GPT 4o에 적용했다 ㅎㅎ
중간에 먹통 돼서 놀랬는데, 다시 잘 돼서 다행이다.

오늘도 마무리!!!!!!!!!!!!!!!
